

В Медицинско-исследовательском институте им. Хантера (HMRI) построена платформа для медицинских исследований на основе ML.NET, использующая цикл с участием человека

Промышленность
Здравоохранение
Размер организации
Большой (1 000–9 999 сотрудников)
Страна/регион
Австралия
Технологии
Компания
Медицинско-исследовательский институт им. Хантера (HMRI) ставит своей целью укрепление здоровья и благополучия членов общества. Для этого институт объединяет ученых, клинических врачей и других медицинских работников, чтобы быстрее создавать новые и улучшенные решения в области здравоохранения.
Медицинско-исследовательский институт им. Хантера (HMRI) ставит своей целью укрепление здоровья и благополучия членов общества. Для этого институт объединяет ученых, клинических врачей и других медицинских работников, чтобы быстрее создавать новые и улучшенные решения в области здравоохранения.
Подробные сведения об исследованиях можно найти в документе "Метод быстрой разработки машинного обучения для интеллектуального анализа данных с участием медика в процессе", Нева Дж. Булл, Бриджет Хонан, Нил Дж. Спратт, Саймон Квилти.
Бизнес-проблема
Медицинские учреждения работают с большими объемами данных. Обычно эти данные имеют вид неструктурированного текста. Даже после оцифровки из них зачастую трудно извлечь значимые аналитические выводы, на основе которых можно действовать. Такие методы, как регулярные выражения, запросы SQL и доступные на рынке готовые программы для обработки естественного языка, применимы лишь ограниченно.
В таких случаях машинное обучение помогает анализировать и извлекать ценные сведения из данных. Средства машинного обучения ранее использовались для классификации клинических заметок по категориям для различных целей диагностики и исследований. Однако для использования этих средств машинного обучения часто требуются навыки разработки программного обеспечения или обработки и аналитики данных. Но эти навыки часто не входят в программу подготовки медиков.
Даже в случае уже обученной модели, если ее оставить работать без наблюдения в реальном мире, она выдает неоптимальные результаты. Поскольку в медицине ставки чрезвычайно высоки, для принятия решений важно, чтобы специалисты-медики могли доверять моделям, а в случае, когда модель ошибается, давать оценку ее работе на основе своего опыта.
Вот почему исследователи из HMRI использовали ML.NET для разработки структуры машинного обучения Human-In-The-Loop (HITL), чтобы медицинским специалистам было проще маркировать данные, обучать модели и использовать эти модели для вывода, не требуя при этом опыта программирования или машинного обучения. Что еще важнее, они создали механизм обратной связи, позволяющий медицинским экспертам использовать свои навыки и знания в процессе машинного обучения. В результате такой высокий уровень контроля позволяет добиться лучших результатов в реальных сценариях использования с меньшим количеством точек данных.
Почему ML.NET?
Компания HMRI использовала Model Builder для начала работы с ML.NET. Model Builder предоставил способ быстро проверить, можно ли решить проблему с помощью машинного обучения. Убедившись в эффективности использования машинного обучения для решения своей проблемы, они воспользовались API автоматизированного машинного обучения ML.NET (AutoML). API ML.NET AutoML автоматизировал выбор алгоритма, а также оптимизацию конвейера и гиперпараметров в рамках собственной среды разработки машинного обучения HITL.
Влияние ML.NET
Компания HMRI использовала Model Builder для начала работы с ML.NET. С помощью Model Builder можно было быстро проверить, возможно ли решение проблемы с помощью машинного обучения. Убедившись в эффективности использования машинного обучения для решения своей проблемы, компания воспользовалась API автоматизированного машинного обучения ML.NET (AutoML). API ML.NET AutoML автоматизировал выбор алгоритма, а также оптимизацию конвейера и гиперпараметров в рамках собственной среды разработки машинного обучения HITL.
Благодаря ML.NET Медицинско-исследовательский институт им. Хантера (HMRI) избавился от необходимости отдавать разработку на сторону и обошелся существующими навыками и ресурсами для выполнения всей сборки внутренними силами.
Кроме того, используя ML.NET как часть решения, исследователи смогли предоставить медикам интерфейс для обучения и использования моделей машинного обучения, не требующий ни умения программировать, ни опыта работы в области машинного обучения.
Архитектура решения
Интерфейс, с которым взаимодействуют пользователи, — это веб-приложение, которое поддерживает несколько задач на этапе обучения и использования модели.
Данные
На ранних этапах данные, использованные для обучения моделей, были получены из исторических медицинских записей. В том числе использовался накопленный за 40 лет набор данных о смертности, содержащий около 30 000 записей, а также набор данных о доставке больных санитарной авиацией, содержащий около 13 000 записей.
Данные хранятся в базе данных SQL Server. Перед обучением специалисты-медики используют веб-приложение для разметки тестового набора в предопределенные категории для вычисления метрик точности во время цикла обучения. Затем для первого цикла обучения используется небольшой набор случайно выбранных данных.
Рабочий процесс обучения, оценки и потребления

Обучение модели запускается специалистами-медиками из веб-приложения. Серверная часть ML.NET проводит обучение и повторное обучение модели. Затем модель прогнозирует все оставшиеся данные. Прогнозы и оценки достоверности хранятся в базе данных SQL Server. Для вычисления метрик точности на тестовом наборе и сохранения их используются хранимые процедуры SQL Server. Специалисты-медики могут просматривать эти метрики через веб-приложение. Весь процесс занимает считанные секунды.
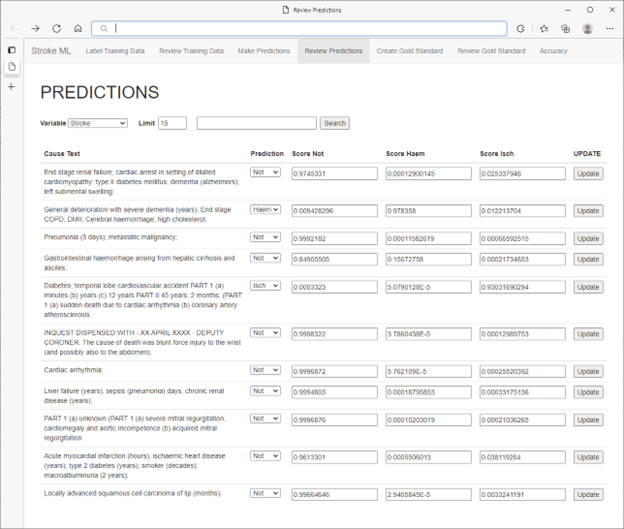
* Не настоящие данные пациентов
Специалисты-медики обнаружили, что им удалось интуитивно использовать метрики отзыва и специфичности в выборе дополнительных вариантов для маркировки, что привело к максимальному и притом быстрому повышению производительности модели. Дальнейшее повышение производительности было реализовано путем выборочного применения меток на основе сортировки по оценке достоверности. При этом специалисты-медики, вовлеченные в активное обучение, не только подтверждают прогнозы с низкой оценкой, но и исправляют неверные прогнозы с высокой оценкой.
На нынешнем этапе медики - специалисты по предметной области - могут запустить задание для повторного обучения модели с использованием исправленных меток данных. Этот цикл "метка, обучение,оценка" повторяется, пока модель не достигает производительности, удовлетворяющей медиков. Метки времени события обучения, метрики оценки и другие сведения заносятся в базу SQL Server для последующей проверки и возможности аудита.
После завершения цикла "обучение, оценка, метка" в базе данных SQL Server с помощью генератора случайных чисел SQL Server выбирается набор прогнозных данных для проверки. Эти точки данных были предварительно классифицированы группой специалистов-медиков, не знающих о прогнозах модели.
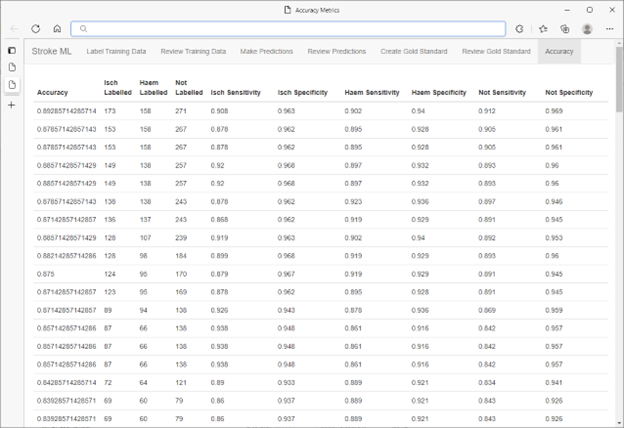
Полученная в результате модель имела точность приблизительно 85-89 %. Этот результат придал исследователям уверенности и позволил использовать классификации, созданные моделью, в текущих медицинских исследованиях. Скорость работы ML.NET в сочетании с рабочим процессом HITL (процесс с участием человека) означает, что модель можно повторно использовать для различных задач классификации и(или) различных наборов данных высокоэффективным и экономичным способом без ущерба для точности.
Планы на будущее
Рабочий процесс с участием врача, разработанный исследователями HMRI, станет незаменим для будущих исследований, в которых очень важна быстрая и точная классификация неструктурированных текстов медицинской тематики.